
Scraping Alchemist: Celery, Selenium, PhantomJS and TOR
Now a days people do scraping for fun and profit, all alike. Scraping is a mean of collecting data from various websites. This data then is often used for various analysis and sometimes the content is republished. There are tools like Selenium WebDriver, CasperJS which allow automated emulation of real user while interacting with browsers, with not much effort.
This post provides architectural overview and avoids code snippets. The Scraper explained in this post, went through multiple iterations. The goals changes forced the product to prove its mettle, adapt and transform. The product evolved as demand increased.
Problems and Problems and Problems and …. #
The scraper faced quite a few problems related to development as well as deployments while it was in its initial days.
The Stone Age #
Initially, it was a browser plugin intended for public release. Data would be sent to pixel tracker while users are navigating on the target website. this data was kept in a file and then loaded into final datastore i.e. HDFS. No Proxy was required.
Problem: As you can see, you don’t know what data you will get and it is all manual.
Somewhere in the Bronze age #
In order to target specific pages, a java + selenium + firefox based monolithic jar was released. It ran on multiple servers with each server targeting different set of pages through configuration. Data pipeline remained the same. Tor was used as proxy and it is still in production.
Problem: Not scalable, Configuration changes were tedious and irritating. Scraper was too slow as firefox is slower to start.
The Iron Age #
In order to speed up the process and have a centralized location for configurations, celery with CasperJS+PhantomJS was used. CasperJS wrote the output to disk which was tailed by SyslogNG and then SyslogNG passed the output to Flume.
Problem: Gaining programming control of CasperJS from python code base proved inefficient as inter-process communication was required. Writing Navigation steps in python became increasingly difficult.
The Scraper Age #
Now, we have combination of selenium, celery, PhantomJS and tor to take care of scraping. Selenium offered more programmatic control, better exception handling and results manipulations. Navigation steps were easier to modify. We could also support multiple browser which help tremendously in development. We can now support plethora of feature requests and bug squashing is fun. So much wow, so much fun!
Problems: Celery/Scraper seems to be slowing down after a but. I haven’t debugged it. But as time demands, I have deployed a magic script which restarts workers every 4 hours. A quick advice from someone well versed with celery can help.
Scraper We Need (in a nutshell) #
This is what we need at the moment.
- Scrape periodically for predefined set of webpages or query parameters.
- Perform requests in near real time [NRT] i.e. in request-response cycle itself to get the insight from scraped data before serving the final response.
- It should be easily configurable.
- Also, there is a need for multiple IPs in order to make detection more difficult.
- Along with it, it should be lightweight and should be horizontally scalable to make it easily cater increase in webpages.
- Ability to support multiple browsers, so that it can be ran anywhere. it would be a great add-on for development, QA and deployment.
- The scraped data needs to be persisted in multiple data stores.
To fulfill the requirements, we came up with following ingredients for sauce:
- Django Admin: To configure webpages to be scraped. Allows to configure multiple pages from a single screen. Support for adding multiple websites.
- Celery: All the tasks [including execution and life cycle] are managed by celery beautifully. Multiple queues for managing multiple flows. Celery workers span across multiple nodes.
- Selenium: Selenium is commander-in-chief which performs navigation steps and actual scraping. Thanks to wide variety of browser support, development and deployment along with QA is swift.
- Python: This dynamic language allowed not only faster roll-outs of product but also easy configurations for switching execution environments.
- SyslogNG and Flume: SylogNG and Flume provides a way to build extensible data pipelines.
- Flask: Flask with Gunicorn and Celery allows to schedule the tasks in real time and the data would be scraped whenever celery worker becomes available. This can be easily extended to actually scrape the data in real time.
- OpenTSDB and Zabbix: For monitoring and alerting, we will utilize Centralized Monitoring system i.e. monster.
- Tor: We all want to be anonymous while scraping, don’t we?
The Flow #
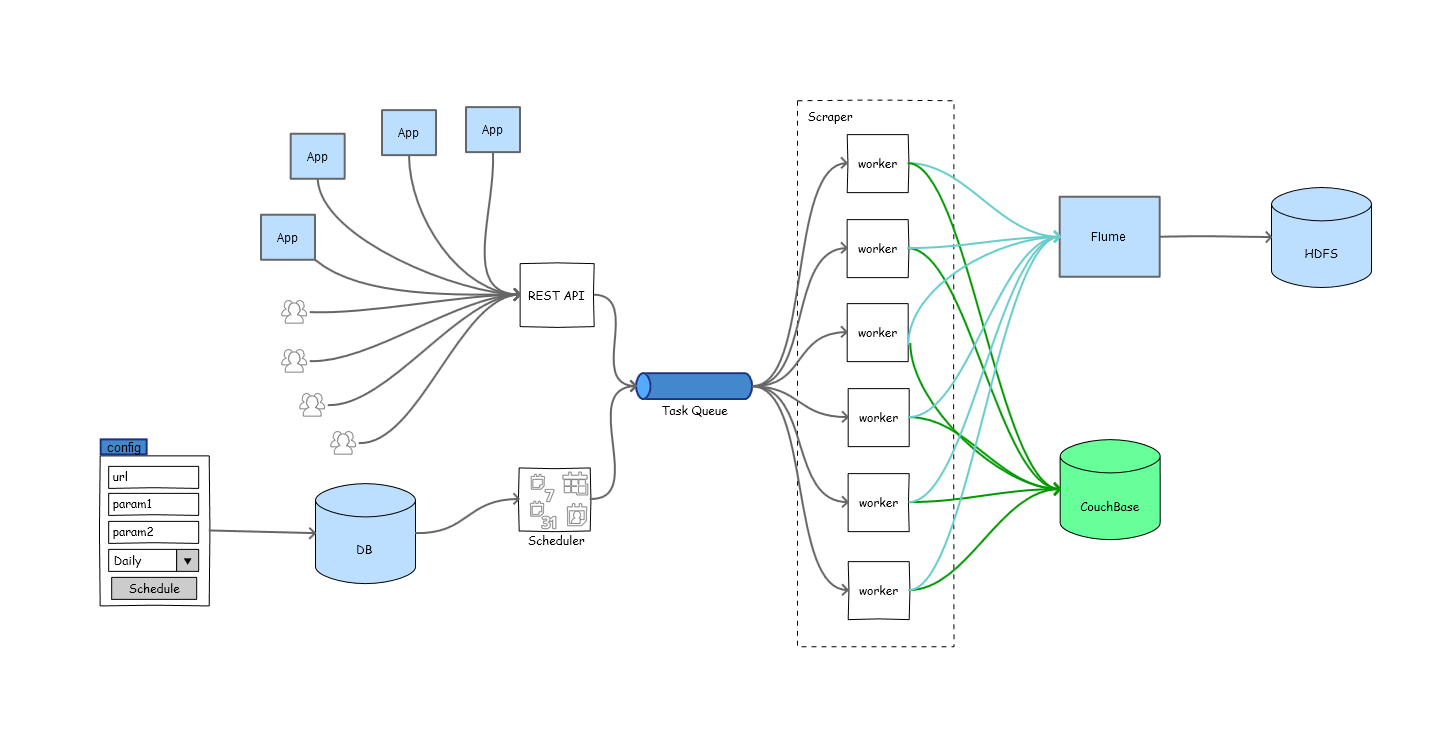 Scraper Pipeline[/caption]
Scraper Pipeline[/caption]
Celery #
- Celery is back bone for the scraper.
It manages all the life cycle for tasks and workers.
- Initialization
- Queuing
- Scheduling
- Task execution
- Retries
- Queue management
It is used with eventlet.
Periodic Task Queuing #
- All the target pages can be configured using admin panel. Admin panel offers form fields which is capable of creating a complete request for the target page. The field can be page number, dates, range of pages, range of dates etc. These configurations are stored in DB.
- Scheduler reads data from DB and creates celery tasks. These tasks are queued in task queue viz. RabbitMQ.
Near Real Time Queuing #
- All the requests for real time scraping are catered from REST API. This REST API takes all the necessary parameters for scraping and schedules it in a queue.
- A storm topology reads data from a Kafka topic and calls REST API whenever filtering criteria for request is matched.
Queues for periodic tasks and NRT tasks are separate and different set of workers work on the tasks.
REST API #
- REST API allows to queue any adhoc request.
- It returns a task id, whose progress can be later tracked by another end point using.
- This task id is UUID generated by celery and all the statuses are that of celery itself.
- Once the tasks are processed, Results are stored in Couchbase which acts as a result back-end for Celery.
Scraper #
- The Scraper constitutes Selenium and Browser. Selenium has APIs for interacting with browser.
- We specify all the necessary navigation steps, form fillings in selenium code to make sure we get the data needed.
- After, the page is loaded, we load a JS into page which fetches the data needed for further analysis.
PhantomJS #
- PhantomJS is deployed in production. Selenium has Ghost Driver to interact with PhantomJS.
- It is headless and hence can be readily deployed in Linux AMIs.
- It consumes way too less resources and faster. There were few crashes. But tradeoff is hard to ignore and in favor of PhantomJS.
- A new browser instance is started every time a new scraping task comes at worker.
TOR #
- All the requests made to websites pass through proxies.
TOR is used as it:
- is free.
- offloads most of the head ache of changing IPs from scraper to itself.
- has region specific configurations.
- has IPs to offer.
Multiple instances with different ports are spawned per node to get region specific proxies.
- Sometimes IPs allocated cause pages to timeouts. Hence that CPU time and cycle is wasted.
Writers #
Each worker has ability to write data to multiple destinations. As of now, it can write to:
- Syslog UDP
- File
- Couchbase
Data can be manipulated before writing to the destination.
Configurations Activator #
- All the components mentioned can be switched on/off or changed by using flags.
- Multiple set of configurations can be maintained for multiple DCs, staging env, dev env or local machines.
- It is easy to replace underlying driver/browser with Selenium and scraper offers easy configuration for such selection.
Flume #
- Flume acts as syslog UDP server and then writes data to HDFS.
- There is a Partitioned Hive table over HDFS which enables easy analysis.
- Flume uses persistent file channel.
Current Status and Future #
This scraper is deployed on AWS with c4.medium machines. Each machine runs 10 periodic task scrapers along with 1 NRT scraper. There is a dedicated t2.medium machine for NRT task, as NRT request usually come in bursts, we can take the advantage of burstable CPU.
New worker nodes can be deployed easily with worker AMIs. For now, scraper age looks good and scraper is able to scrape 10x pages in the same resources as that of bronze age, which can be further improved by reusing browser instances and privoxy to change TOR IPs.
At the moment we are spending time on building storm topology which schedule a task in NRT queue. Admin panel is now more flexible with room for more configurations. Next nice to have thing for scraper is Auto-scalability. But before that we need to start pushing stats into OpenTSDB and maintain task statuses in a DB.