
Hive Partitioning: Tips and Hows
After having used Hive for sometime now, I can really say, it has provided some serious productivity boost. Not only that, it is really easy to maintain and most of the things are transparent to the developer. Really huge amount of data can be efficiently crunched using Hive!
Hive Partitioning: An Overview #
By design, Hive is a DWH built on top of HDFS and MR. It is built for very large datasets. Behind the scene, Hive also spawns MapReduce. With existing data volume and velocity at which new data is flowing in would cause system to reach a point where processing would end up hogging all the available resource.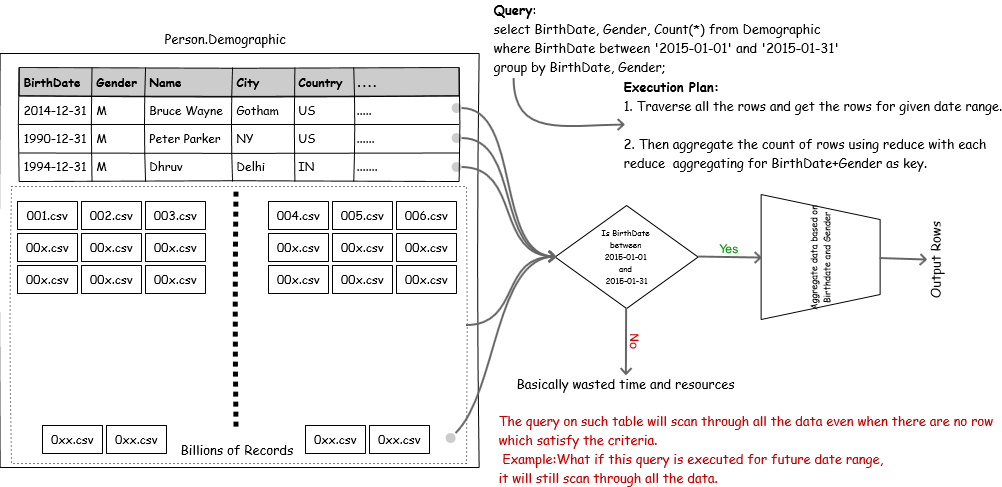
Lets imagine a scenario, if we were to dump all the access logs from servers to HDFS, we will simply build a hive table on top of it. The data will start flowing in it on daily basis. We start appending data to HDFS directory. Six months later, some issue occurs in production and only one week duration of access log data is required for its analysis. We will need to execute query on date column which will iterate over all the rows from all the files in the HDFS dir. A full table scan is performed for such a trivial task. Wouldn’t it be nice to have feature which will allow us to readily fetch data for only those seven days? Hive partitioning provides exactly that!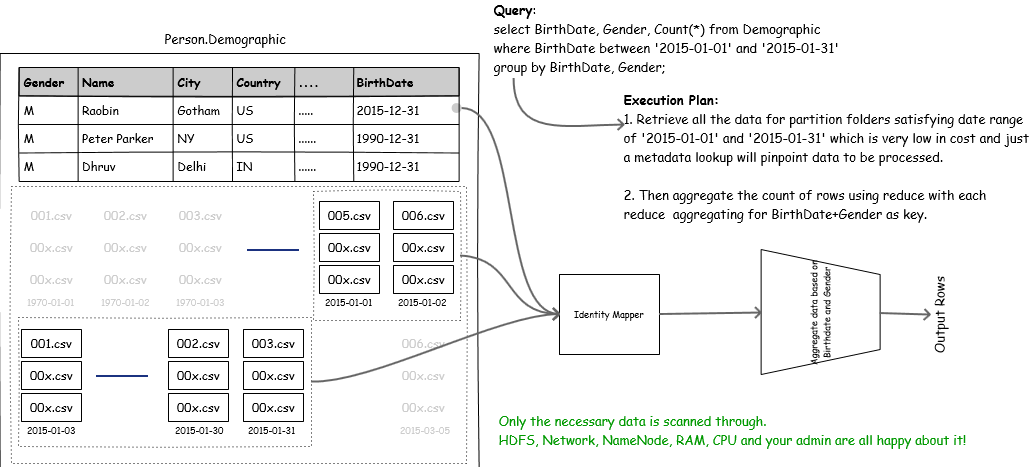
Generally a MapReduce program reads all the files provided as input and then as per code logic, it starts applying filters, aggregations, etc. For large data sets this method is very inefficient. In most of the cases, table users know the frequently used columns for querying.
For example: Most of the time, queries performed over log data have date in where clause. Sample query for access logs would be “give me all the 404 which occurred yesterday”.
In such cases it makes sense to make all frequently queried column related data readily queryable! Hive partitioning helps in organizing such data in separate directories. As a result, all the data related to a particular column value is put under a directory. When a query is executed with partition column in criteria, instead of performing a full table scan, all the data belonging to that partition directory is fetched and processed which greatly reduces amount of data crunched.
Lets see how to create a partitioned table and ways in which data can be pumped into it. Then how can we use partitions efficiently and what precautions we should take while dealing with partitions.
Defining a Partitioned Table #
Hive language manual is one of the very well written documentation on www. It clearly explains every little detail in a very intuitive manner. Lets use it and create a table which is partitioned. We will use the same case explained earlier. The demographic table would be partitioned by BirthDate column.
While Creating Table #
Most of the time we know details about data which is going to flow in system. Hence, we can instruct Hive to create partitioned table.
Syntax:
So demographic table DDL will look like:
|
|
What is the difference between unpartitioned table and partitioned table in this case? BirthDate column would become a pseudo column. Actual files will not contain any data for Birthdate, rather it will be derived from directory name.
When our table is partitioned by Birthdate then we will have directory /app/person/demographic/BirthDate=2015-01-01 and this directory will have following structure when selected from hive query.
| Gender | Name | City | Country | BirthDateTime | BirthDate |
|---|---|---|---|---|---|
| Male | Jack | NY | US | 2015-01-01 01:23:39 | 2015-01-01 |
| Male | Kent | LON | UK | 2015-01-01 04:43:40 | 2015-01-01 |
| Female | Rossie | SYD | AUS | 2015-01-01 12:31:30 | 2015-01-01 |
You can execute query with partition column in where clause and you can see huge performance boost. If all partitions are uniformly sized and there are about 1000 partitions, it will take only 7/1000th of cumulative CPU time as compared to the case of non partitioned table.
Adding Data to Partitioned Table #
Using Staging Table #
In this strategy, we create a staging table to temporarily host the data and then we move data to final partition.
|
|
As you might have noticed, staging table does not have any partition column, well in some use cases it is possible to create a partition column for temp table as well. To add data to temp table, we just put the data into the table location. Then using INSERT INTO ... SELECT query insert data into final table with correct partition.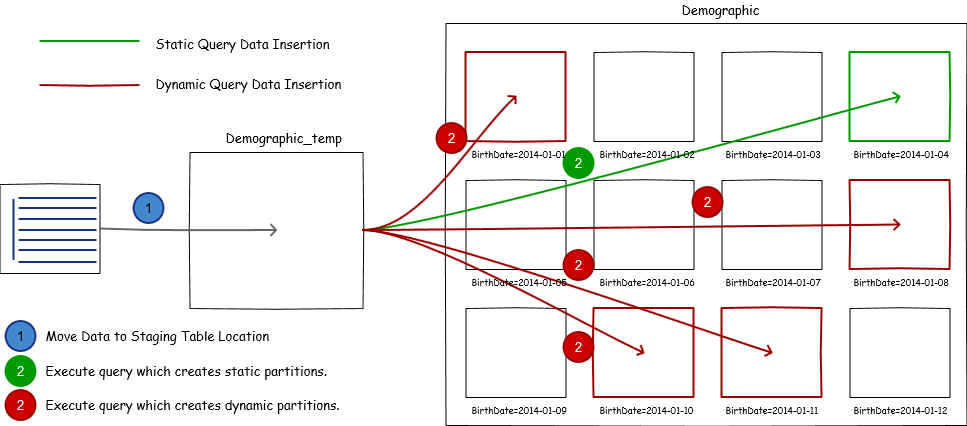
We can use both static and dynamic partitioning with this strategy. They are explained in more details in subsequent section. Data transformation and cleanser can be applied while selecting the data from temp table, which adds extra flexibility. Most of the times partitioned tables carry Hive specific data formats such as ORC which are also compressed. This method supports data conversion out of the box.
Load Data Inpath #
File can be directly moved from HDFS directory to partitioned table using LOAD DATA INPATH 'filepath' INTO TABLE Demographic PARTITION (BirthDate='2014-01-12')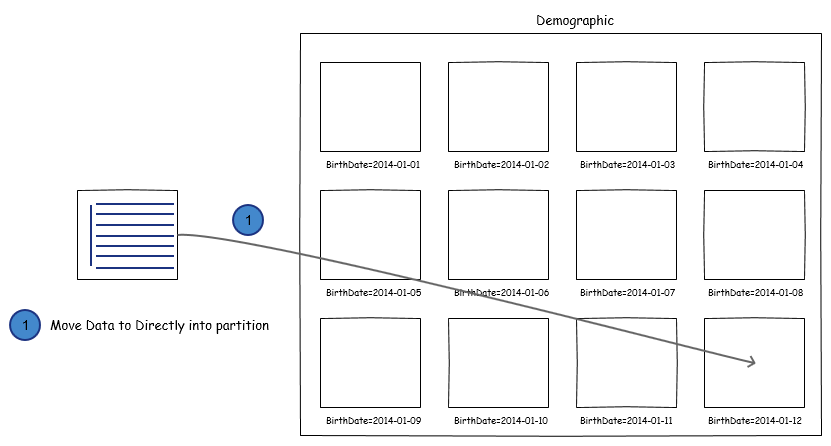
This is a pure copy operation which means, we won’t be able to apply any data transformations, file format conversions and dynamic partitioning.
Copy Data Data and Perform Alter Table #
This is very similar to Load Data Inpath method. But in this method we copy data manually to partition directory and then alter table to add this directory using ALTER TABLE ... ADD PARTITION query.
|
|
We do not need to follow naming convention for this method to work. But generally you should.
Partitioning Methodology #
The nomenclature static and dynamic depends on whether partition value is derived at runtime or at compile time.
- Static Partitioning: The value of the partition key is provided along with the query itself. Hence, we know the exact value at the compile time itself.
- Dynamic Partitioning: The value of the partition key is derived at run time from query execution and partitions are created on the fly.
Static Partitioning #
Static partitioning is useful when you know exactly to which partition data in hand belong. Suppose you get a file on a daily basis for yesterday’s data feed. Then one can easily load data in partition which is for yesterday’s date[example:’2014-01-01’]. First load data in staging table i.e. DEMOGRAPHIC_TEMP and then load it into main partitioned table i.e. DEMOGRAPHICINSERT INTO TABLE DEMOGRAPHIC PARTITION (BIRTHDATE='2014-01-01') SELECT * FROM DEMOGRAPHIC_TEMP
As you can see, we have already mentioned partition date and Hive only has to move data to this directory.
Dynamic Partitioning #
Most of the time, we need to consume files which have data for multiple partitions. It is inconvenient to separate data for each partition by filtering and then add this data one by one by using static partitioning. Hive provides a very useful feature of dynamic partitioning. You just need to use INSERT INTO ... SELECT syntax with few dynamic partitioning related parameters set. Hive will automatically filter the data, create directories, move filtered data to appropriate directory and create partition over it.
Parameters which should be set:
|
|
The methodology would remain the same,first load data in staging table i.e. DEMOGRAPHIC_TEMP and then load it into main partitioned table i.e. DEMOGRAPHICINSERT INTO TABLE DEMOGRAPHIC PARTITION (BIRTHDATE) SELECT *,to_date(BIRTHDATETIME) FROM DEMOGRAPHIC_TEMP
We have only mentioned partition column and It’s Hive’s responsibility to add data to appropriate directory. Hive will use last column to deduce the partition for data. As you can see, I have used to_date UDF to convert ‘2014-01-01 02:02:20’ to ‘2014-01-01’. That is because I do not want to end up creating partition at second’s granularity.
If SELECT to_date(BIRTHDATETIME) FROM DEMOGRAPHIC_TEMP GROUP BY to_date(BIRTHDATETIME) gives four values, then four partitions would be created for those four values.
Conclusion #
With fairly huge dataset, it would take ages to perform even simpler queries. But with the help of Hive partitioning, we can perform queries more efficiently where only subset of data is data to be processed. Hive provides greater flexibility to create partitions, maintain partitions and remove them if necessary.
I have also seen some extra advantages such as ability to clean data for only few partitions. I would have had nightmares if I had to do it for nonpartitioned tables.
But still if someone wants to query complete dataset then hive partitioning is not going to help. As well over partitioning can end up causing more troubles than gains. With great power comes , great responsibility.
Tips and Precautions #
Hive can be used to advantage, if we follow good practices and take some precautions. Taking into consideration, NameNode capacity, available resources and gain we want from partitioning we can make a call about table definition.
- Do not Abuse Dynamic Partitioning: Dynamic partitioning is a great addition to Hive. But it is too easy to abuse it. Suppose, I know that a particular dataset belongs to a particular partition. If in this case, I use dynamic partitions, then I am spawning unnecessary Reducers to partition data making process inefficient.
- Use of
MSCK REPAIR TABLE: If we have data in appropriate format i.e. in tables FileFormat and we know exact partition for that data then we can just create a directory with proper naming convention in table location and performMSCK REPAIR TABLE TABLE_NAMEto add those partition to table. This is particularly useful when I am moving data from one location to another. Also if in case few partition directories were removed and table is external, then table’s metadata won’t be updated automatically. So Hive will still be looking for this partition folder and error out. To prevent this from happening, performMSCK REPAIRand you should be good. - Prohibit Yourself from Overwhelming NameNode: While making use of dynamic partitioning, one should take care of no of partitions which could be generated as a output of
SELECTquery. If too many partitions are produced then Hive will try to create that many directories and move files to those directories putting strain on our beloved NameNode. - Use
INSERT OVERWRITE ... SELECTCautiously: This one holds true for dynamic partitioning. If file being processed dynamically contains only few rows in source table for already existing partition in destination table, then you run into risk of that data being overwritten. This approach has the potential of data loss. If there are multiple partition columns, then you can partially specify partition column value to lower the risk. - Include Partitioned Column in
WHEREclause: To use partitioned column properly, one should always include it in theWHEREclause. Otherwise, partitioned columns are pretty much useless. - Check of Cardinality of Data: Data partitioning with high cardinality is going to create large number of partitions with very small amount of data in it. NameNode and in turn your cluster admin are not going to like it.
- Do not create too many [Nested] Partitions:This is same as that of cardinality of data.
- For small dataset, better off with unpartitioned table: Smaller datasets should not be partitioned. You won’t loose much performance by not partitioning the data.
- Apply Transformations, if necessary: Apply transformations before creating partitions dynamically. Staging table approach can easily deal with most of the transformation requirements. One example would be to convert DateTime column to Date column. Trim the data, as values with spaces would be treated as valid values.
- Keep Raw fields, if you can: If you are going to apply transformations before creating partitioned column value, make sure you also keep raw data as well. If DateTime column is converted into Date column then it would be impossible to perform query which needs Hourly resolution.