
HDFS: How a file is written!
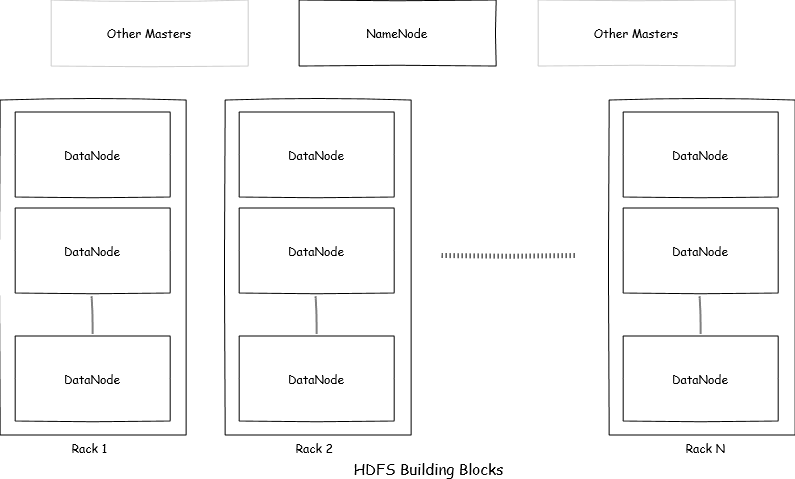
HDFS is distributed file system capable of storing very large files without much effort. HDFS spans across multiple machines on multiple racks. There are two types of nodes in HDFS:
- DataNode
- NameNode
The nodes responsible for storing files and handling IOs are DataNodes where as NameNode is responsible for keeping the fs image and upkeep of the HDFS. HDFS is robust, highly flexible, faster, fault tolerant, easier to maintain, easier to scale out and reliable. Various decisions made while designing HDFS are responsible for such features and it makes HDFS suitable for many usecases. Lets have a brief look at how HDFS is designed and how file is written internally.
HDFS provides a very easy API for interacting with the files stored in it. HDFS can be queried from command line, code and over web. To add sugar coating, its file system commands resemble linux file system commands and it also hide away the internal complexities of distributed file system. For example, if you want to read a file from HDFS then execute hadoop fs -cat /path/to/file/on/hdfs which is very similar to cat /path/to/file in linux. A single file is distributed across cluster and can be accessed with the help of API. HDFS takes most of the pain while interacting with the client. The same thing happens when you push a file to HDFS.
Essentially, all IO commands issued to HDFS inolves multiple steps and they are highly optimized for maximum throughput and reliability. While writing a file to HDFS, one can simply exeute hadoop fs -put /path/to/file/on/local /path/to/file/on/hdfs and HDFS will make sure the file is written to multiple nodes. HDFS also maintains metadata of these blocks so that files can be read from it.
Have you ever wondered, what really goes on behind the scene while you execute these commands? Well, whatever happens HDFS shouldn’t stay in HDFS and we should definitely know about it. Lets dive deep to see how a file is written on HDFS.
Writing a file to HDFS #
Lets have a look at how file can be written to HDFS with the help of command line tool. You can choose to write the file using web API, programmatically or through command line but the internals will remain exactly the same.
From Low Earth Orbit: #
To write a file to HDFS one should execute -copyFromLocal, -put, -appendToFile with appropriate arguments and options. Done! File is split into blocks and then those blocks are placed onto HDFS on different DataNodes.
From 36000 feet: #
When we execute one of these commands, client should know to which namespace it needs to write the file. It means, it need to know the NameNode seating on top of that namespace. Client connects to NameNode, get the DataNode addresses which are going to host the files and transfers the files on those DataNodes.
If there were five blocks and replication factor of three, then HDFS with five DataNodes will store blocks such that unavailability of any of the node won’t cause any data loss.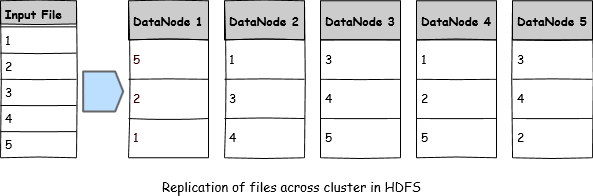
Even if DataNode 2 Goes down, the files are still available on other nodes. Hence we still have data and then HDFS can re-replicate the lost blocks.
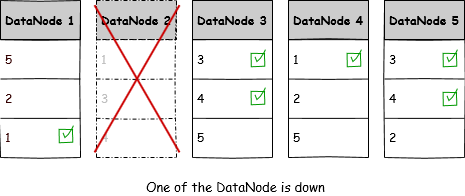
Replication also helps us increase data locality. It also helps in MapReduce principle which says “Process should travel to data as it is cheap and not the other way around”.
From 5000 feet: #
Well, the data has been broken to blocks, written to multiple nodes, it has been replicated and now we can start reading it from HDFS, This raises few questions!
- Who decides the replication factor and block size?
- Who breaks the file to blocks?
- How data is written to DataNodes and essentially, how it is replicated across cluster?
- How replicas are placed, how DataNodes are chosen for given file block?
- How optimized utilization of resources is ensured?
Lets drill down a bit for answering these questions.
Replication Factor and Block Size: #
By default, HDFS has a replication factor of 3 and block size of 64 Mb. These properties can be changed at the time of setup. dfs.replication and fs.block.size from hdfs-site.xml are responsible for these properties. If cluster is already operational and you decide to change these properties afterwards, existing blocks on the cluster will remain unchanged and only affects newly added blocks to the cluster.
Client receives these settings from NameNode DataNode. These are file-level settings implying client has ability to override these properties per file basis. Client then breaks file into blocks as it starts process to store it in HDFS.
Writing Data: #
After getting all configurations, client asks NameNode for list of DataNodes on which it should host the blocks. Blocks are sequentially written to HDFS and for each block NameNode provides list.
The flow diagram explains the process.
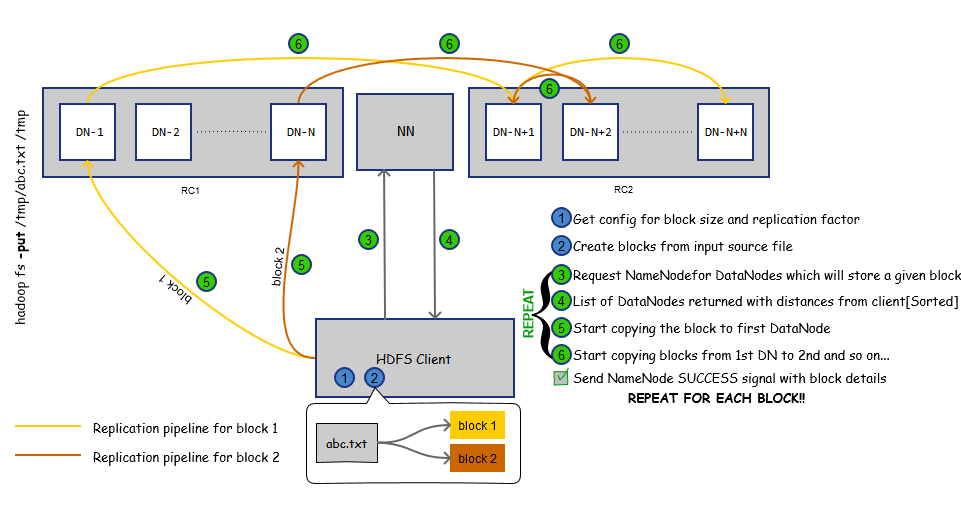
HDFS forms a replication pipeline when data flow starts from client. This replication pipeline ensures that the needed replication factor is met.
In the flow diagram above, client starts streaming packets to the DN-1. DN-1 in turn transfers these packets to other DataNode and then that data node transfers the data to subsequent DataNode if necessary. These DataNodes start transferring packet as soon as they receive a data packet completely. Data packet is buffered at each hop in the pipeline. The client do not wait for acknowledgement from these DataNodes and starts to transmit another packet irrespective of status of previous packet. Client also sends checksum for each block written to the HDFS which helps in ensuring the integrity of the data.
Once the data block has been streamed completely to the DataNode, that DataNode sends report to NameNode.
Then this process is repeated for another block in the file. All the blocks have same size except for last block. When all blocks have been written to HDFS, NameNode finalizes the metadata and updates the journal file.
I have left out concept of lease, hflush/hsync and close,Write Once Read Multiple concept, checkpoint, journal, fsimage as these are not in the scope of this article.
Choosing DataNodes: #
HDFS is rack aware and forms a network topology based on rack along with DataNode configurations. Once DataNodes have been associated with a particular rack, HDFS can then use its algorithm to deduce on which node the data should be stored.
Lets see how this algorithm works:
HDFS calculates network topology distance of each node from writer client. When a new block is created, it places the first replica on the node where the writer is located. The second and the third replicas are placed on two different nodes in a different rack. The rest are placed on random nodes with restrictions that no more than one replica is placed at any one node and no more than two replicas are placed in the same rack, if possible. The choice to place the second and third replicas on a different rack better distributes the block replicas for a single file across the cluster. If the first two replicas were placed on the same rack, for any file, two-thirds of its block replicas would be on the same rack.
After all target nodes are selected, nodes are organized as a pipeline in the order of their proximity to the first replica. Data are pushed to nodes in this order. For reading, the NameNode first checks if the client’s host is located in the cluster. If yes, block locations are returned to the client in the order of its closeness to the reader. The block is read from DataNodes in this preference order.
This policy reduces the inter-rack and inter-node write traffic and generally improves write performance. Because the chance of a rack failure is far less than that of a node failure, this policy does not impact data reliability and availability guarantees. In the usual case of three replicas, it can reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three.
Algorithm takes following parameters in consideration:
- Whether selected node is free, if it is not then chose another.
- If given node has free space left.
- Health of the given node.
Algorithm does not take into consideration:
- If data transfer is going to keep size of HDFS uniform across nodes i.e. balanced.
- Network bandwidth between two nodes.
Algorithm ensures:
- Data is kept onto multiple racks as per rack placement policy.
- Minimizes the write cost.
- Maximizes data reliability, availability and aggregate read bandwidth.
HDFS carries arsenal of tools with it to ensure data is always available in required form. Be it block scanner, balancer, replication manager or extra NameNodes serving as CheckpointNode/BackupNode, everything is very well orchestrated and hence HDFS is the most adapted file system for Hadoop.
References: #
http://www.aosabook.org/en/hdfs.html
https://hadoop.apache.org/docs/r1.1.1/api/org/apache/hadoop/net/NetworkTopology.html
https://hadoop.apache.org/docs/r2.3.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
http://static.googleusercontent.com/media/research.google.com/en//archive/gfs-sosp2003.pdf